I will explain here my latests experiments with implementing the MLP model I talked about in this post. The main idea is to implement the function 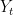

Training and validation sets
First I will start with explaining the dataset I used for training the model. You can find the code for dataset preparation script here. The input in each training example is composed of a fixed number of acoustic samples (e.g. 600 samples, which is equivalent to 2.5 frames of 240 samples) and one-hot representation of two phonemes corresponding to the current frame (current window of phonemes). The target is just the following sub-frame (e.g. 40 samples). In the experiment below I used data of 10 speakers, with 60 input samples, where each sample is a float in [-1,1], and 39*2 floats in {0,1} for one-hot representation for two phonemes. The target is 40 floats in [-1,1]. This dataset has 221,530 examples, and that’s again only for 10 speakers! It’s clear that we need an efficient (RAM-wise and CPU-wise) way to deal with data that what’s being done by Vincent. Validation set has the only 5 sentences from one speaker.
The MLP for
I used an MLP with 2 hidden layers each has 300 units with tanh activations. The activation function for the output is also tanh. I trained the network using learning rate 0.01 (I am annealing the learning rate linearly to 0 starting after 30 epochs), 100 samples per mini-batch, and L2 regularization term 0.0001.I haven’t done a hyper-parameter optimization on the grid, but I have tried several configurations for the size of the layers and even changed activation of hidden layers to rectifiers (I used GPU to run the experiments quickly), and this is the setting I found to perform best. The following figure shows training and validation error.

The errors are very close and the model is clearly underfitting. I am not sure though why validation error is very close to training error though. The lowest error is 0.000816 and if you convert that into the scale of the original samples it turns out to be ~517.
Generating speech
In order to generate speech using this frame prediction model we really need something to give us a good alignment between phonemes and acoustic samples, and that’s what we want

Although the result is not impressive, I like that the model is able to capture some variability. The main problem I see here is the generated signal has much higher frequency and much lower amplitude. You can listen to the generated sound here. It sounds more like music! but you can still hear the variability. The code for the speech synthesizer is found here.
What’s next?
There are many directions for improvement. First, I want to train the model with the full dataset, so I need to check out Vincent’s data wrapper. I would like also to add more features to the input, for example the position of the current frame in the phoneme window, also I want to add speaker information. Another very important aspect is looking into better representation of the frames, which might be more robust to errors in prediction.

The link to the wav doesn’t seem to work.
Wow, the generated sound is really weird but cool.